OpenTelemetry context propagation in FerretDB


In today's world of distributed systems, achieving reliability depends on various factors, one of which is effective observability. OpenTelemetry (OTel) has emerged as a standard for distributed tracing, but passing tracing data to databases remains a significant challenge, particularly with document databases like MongoDB. At FerretDB, we're committed to addressing this challenge.
OpenTelemetry context propagation for databases
Context propagation, a concept that enables the tracking of requests as they move through different services, is explained by OpenTelemetry here. This context typically includes request-related data, such as trace identifiers, which are passed across service boundaries, allowing you to link different parts of a distributed request together. The most common approach to implement context propagation is by using trace context HTTP headers to pass this information between services, but this method is not always feasible.
Obviously, most databases don't support such HTTP headers or other native ways to pass tracing-related context. Approaches like SQLCommenter have been developed to bridge this gap, enabling the connection between current trace data and database queries. In these cases, trace information is injected at the ORM level and passed to the database via SQL comments. Database operators can then enable query logs to link specific queries with the corresponding application requests.
But is it possible to achieve something similar with MongoDB's query language? At FerretDB, we believe that enabling the linking of a query's lifecycle with the caller's response can help developers make their applications more predictable and reliable.
FerretDB's approach to context propagation
Let's consider a SQLCommenter-like approach for MongoDB. We can leverage MongoDB's existing features to attach metadata to queries. One such feature is the comment field, which allows additional information to be included in MongoDB queries. This field doesn't influence query logic but can be used to provide valuable context.
At FerretDB, we want to empower users to pass such context.
We decided to utilize the comment field to do it.
We parse the content of the comment field, and if it's a JSON document with a ferretDB key, we check for tracing data.
If the tracing data is present, FerretDB sets the parent context for a span created for the current operation.
An example of a comment with tracing data could look like this:
{
"ferretDB": {
"traceID": "1234567890abcdef1234567890abcdef",
"spanID": "fedcba9876543210"
}
}
Using this approach, it's relatively easy to visualize client's requests to FerretDB showing them as part of the original client trace.
However, there are some limitations.
Not all operations support the comment field.
For instance, operations like insert or listCollections do not support it.
Another challenge with the comment field is its handling in some MongoDB drivers, where it is typed as a string.
This means that, in principle, any string can be passed.
In our scenario, where we allow FerretDB to receive and parse
tracing data through the comment field, the JSON must be correctly encoded by the driver and then decoded by FerretDB.
A more robust solution would involve having a dedicated field for passing request-related context, and it would be ideal to establish a standard for such fields within Trace Context Protocols Registry. For instance, it could be a BSON document with particular tracing-related fields. This would provide a more reliable method for passing context to the database.
Example application
Since such a standard does not yet exist, let's explore an example application
that interacts with FerretDB and passes the tracing context using the comment field.
For simplicity, most error handling is omitted in the example below.
collection := client.Database("testdb").Collection("customers")
user := bson.D{
{Key: "name", Value: "John Doe"},
{Key: "email", Value: "john.doe@example.com"},
}
insertCtx, insertSpan := tracer.Start(ctx, "InsertCustomer")
_, _ = collection.InsertOne(insertCtx, user)
insertSpan.End()
findCtx, findSpan := tracer.Start(ctx, "FindCustomer")
filter := bson.D{{Key: "name", Value: "John Doe"}}
_ = collection.FindOne(findCtx, filter)
findSpan.End()
In this setup, we create two spans: one for inserting a document and another for finding it.
If we run this application, we will see that the spans for the InsertCustomer and FindCustomer operations are created:
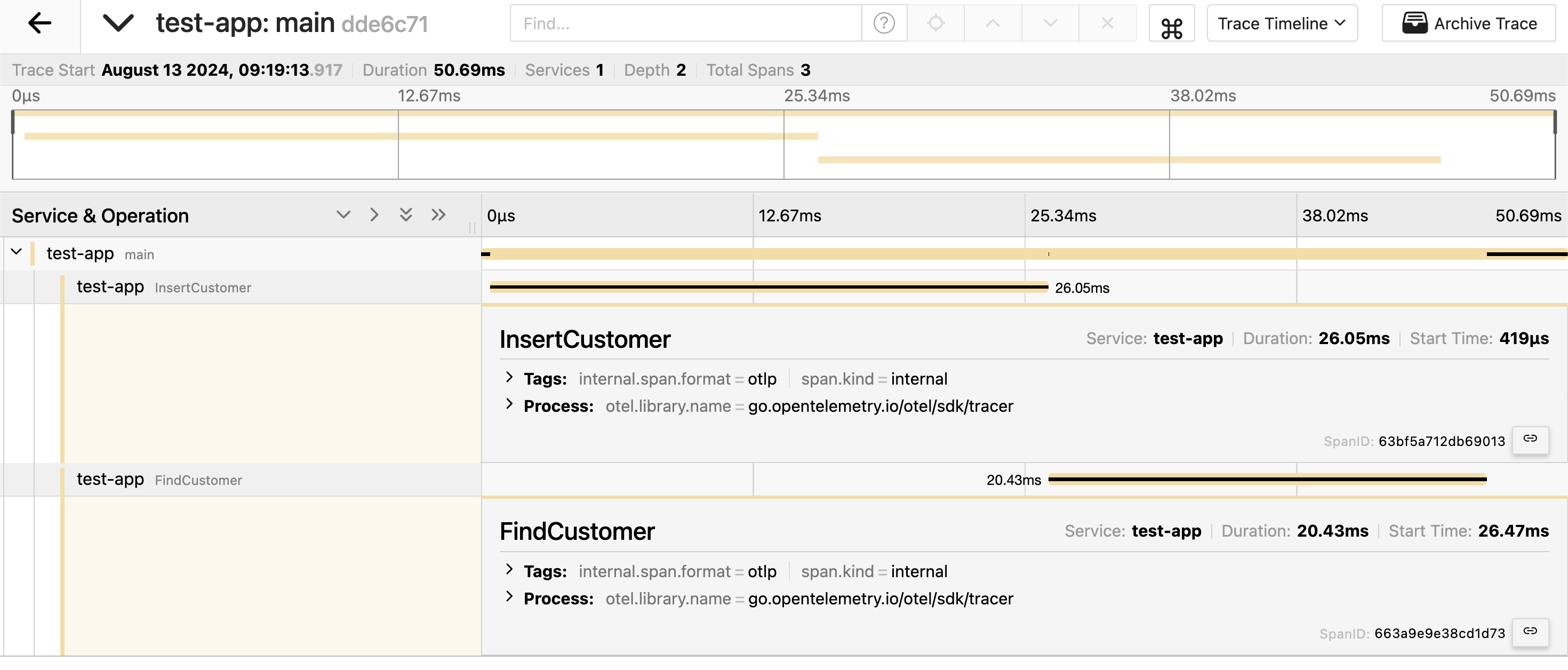
Let's add more details.
If we pass the tracing context through the comment field, we will see that the spans are linked.
Let's modify the FindCustomer part:
findCtx, findSpan := tracer.Start(ctx, "FindCustomer")
filter := bson.D{{Key: "name", Value: "John Doe"}}
traceID := findSpan.SpanContext().TraceID().String()
spanID := findSpan.SpanContext().SpanID().String()
comment, _ := json.Marshal(map[string]interface{}{
"ferretDB": map[string]string{
"traceID": traceID,
"spanID": spanID,
}
})
_ = collection.FindOne(findCtx, filter, options.FindOne().SetComment(string(comment)))
findSpan.End()
Now, if we run the application, we will see that the spans created in the application and in FerretDB are linked.
The FindCustomer span has a child span find created on the FerretDB side:
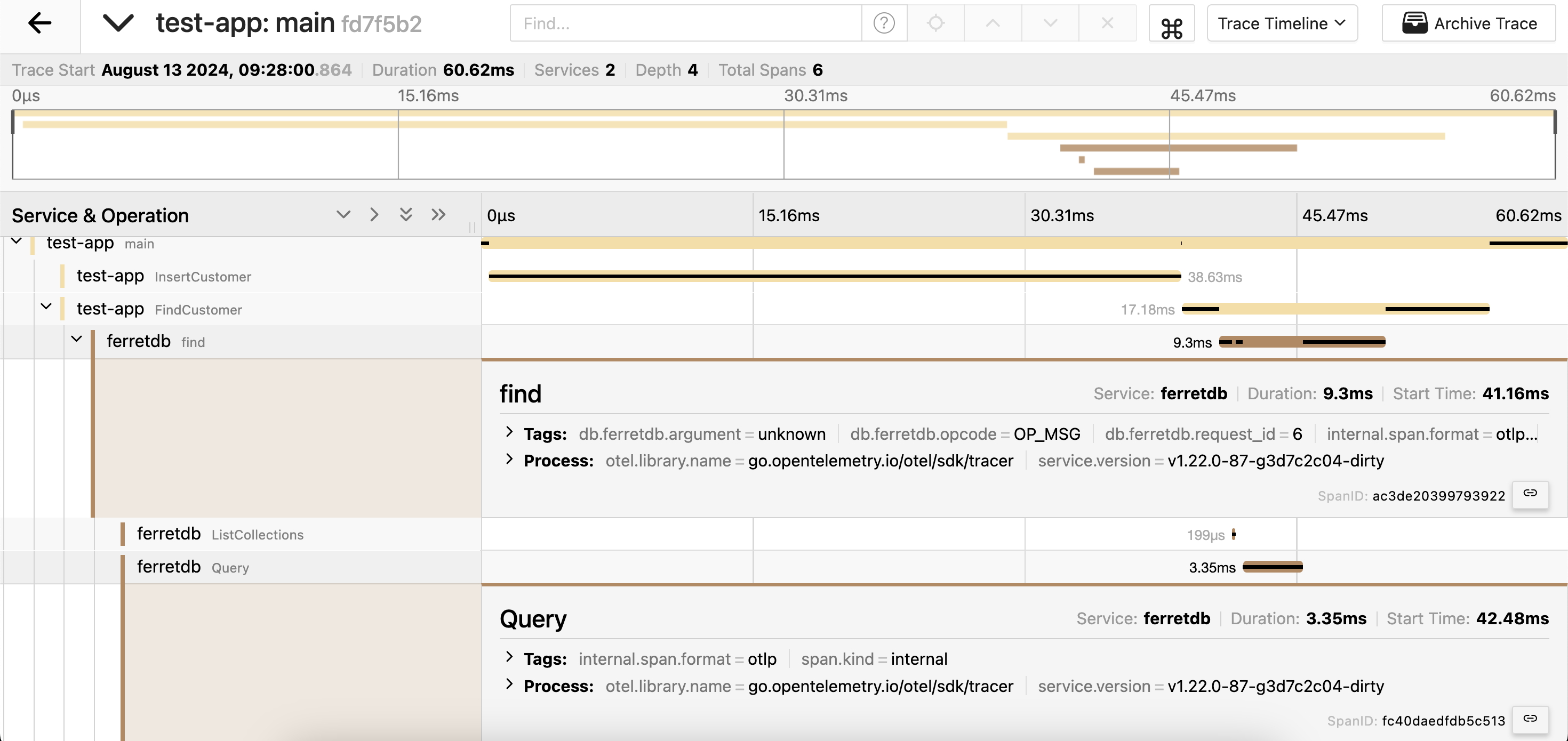
This approach gives more insights into the FerretDB's behavior and helps to understand the exact query lifecycle, making it easier to diagnose and understand performance issues or unexpected behavior.
While this solution isn't perfect due to the limitations discussed, it is a step towards better context propagation in document databases.
Conclusion
We believe that passing context to document databases is an important part of making them more observable. We hope that the community will come up with a standard way to do it, and we are looking forward to contributing to this effort. Ideally, it would be great to extend Trace Context Protocols Registry with a protocol for passing context to document databases.
We'd love to hear your thoughts on this approach. Have you implemented similar context propagation strategies in your projects? Please feel free to reach out to us here to share your experiences or ask questions!