FerretDB v1.10 – Production-ready SQLite support and more


We just released the new version of FerretDB – v1.10, which is available in the usual places. With it, the SQLite backend support is officially out of beta, on par with our PostgreSQL backend, and fully supported.
In the past two weeks, we added support for many missing commands and features, including aggregation pipelines, indexes, query explains, and collection renaming. Please refer to the full release notes for details.
There are still opportunities for improvement, such as support for more query pushdowns, but they will not break the compatibility. You can start using the SQLite backend in production now! It is ideal if you need a MongoDB-compatible database that could work in environments where MongoDB can't.
You may wonder how we made such huge progress after a few relatively quiet releases. That's because we worked on the new FerretDB architecture in the background, and the new SQLite backend is the first part of it. Let's talk about it.
The new architecture
When FerretDB (née MangoDB) was first released, it supported a single PostgreSQL backend. The simplified version of the architecture looked like this:
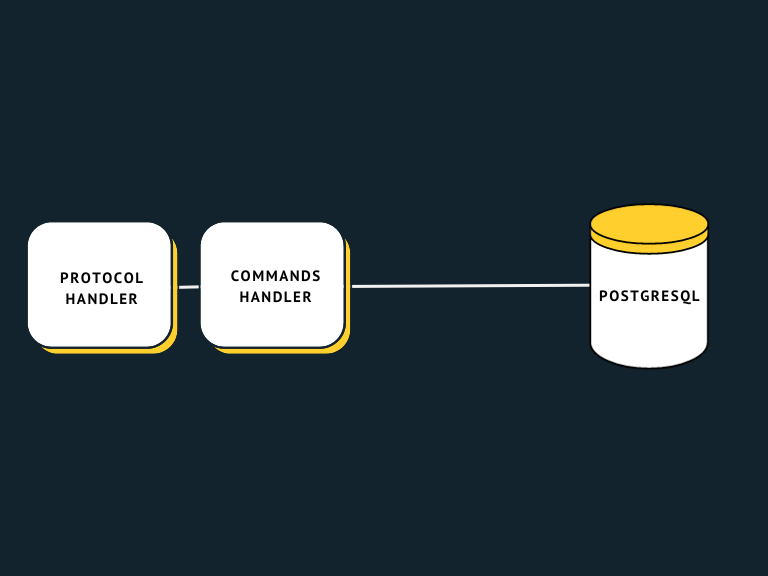
The protocol handling module was (and still is) responsible for handling client connections, MongoDB wire protocol,
and BSON documents encoding/decoding.
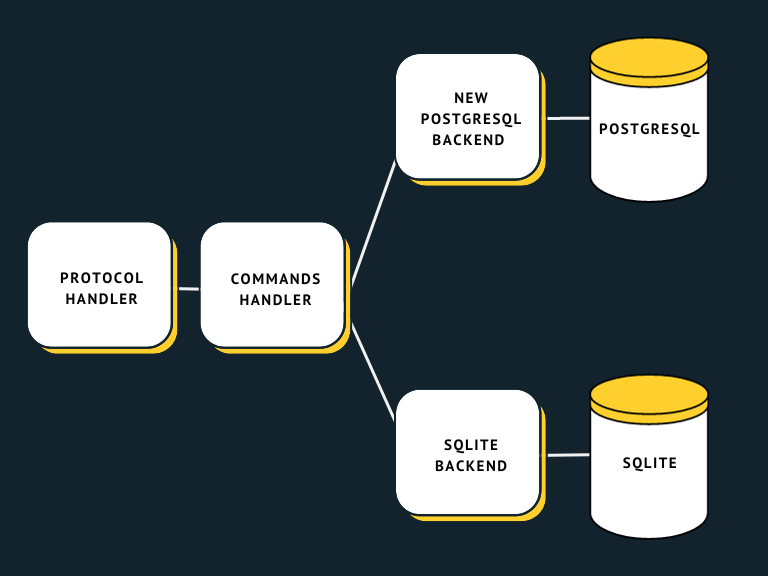
The commands handling module was responsible for handling protocol commands such as find, update, and delete.
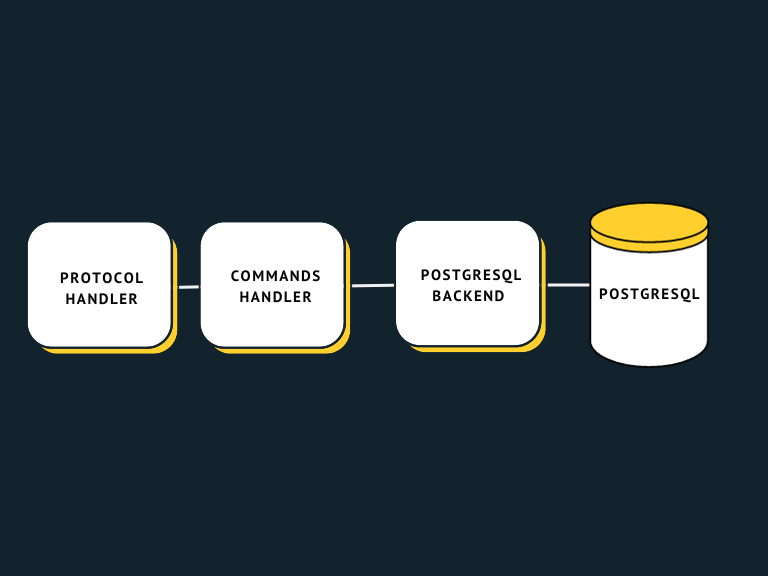
Over time, we understood that there is some common code between command handlers. We extracted a part responsible for accessing PostgreSQL and running queries into the backend package:
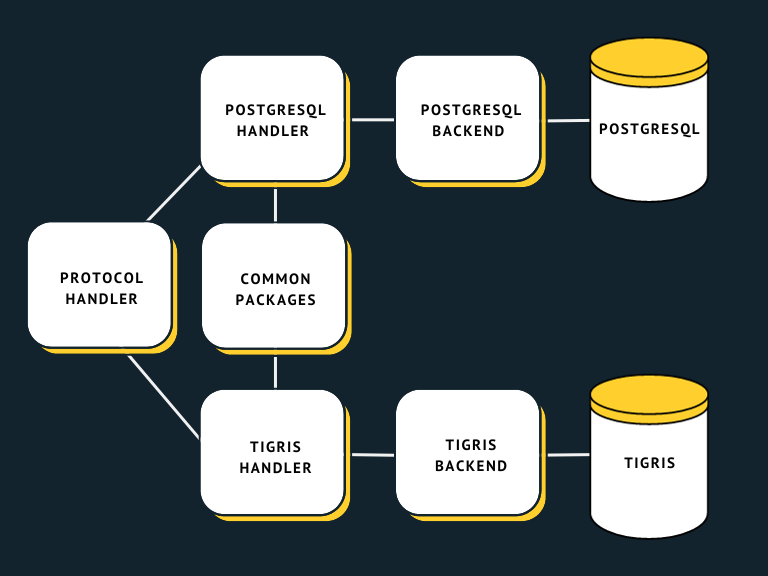
When we added another backend, we could not figure out if there was a common interface for different storages as they were so different. So we decided to make another commands handling module that was similar in things like command parameters extraction but very different in the way it interacted with storage. Similar parts were extracted into a set of common packages:
Over time the common part grew, but we still had very different backend packages. When we decided to add SQLite support, we wanted to revisit our previous decisions – could we design a common storage interface after all? We did not expect many people to use SQLite with a lot of data, so performance could have a bit lower priority, and the interface could be relatively simple. At the same time, we had a lot of practical knowledge of how FerretDB is used with PostgreSQL backend, what is important and what is not, and what problems the current backend has and how to avoid them. So we settled on this architecture:
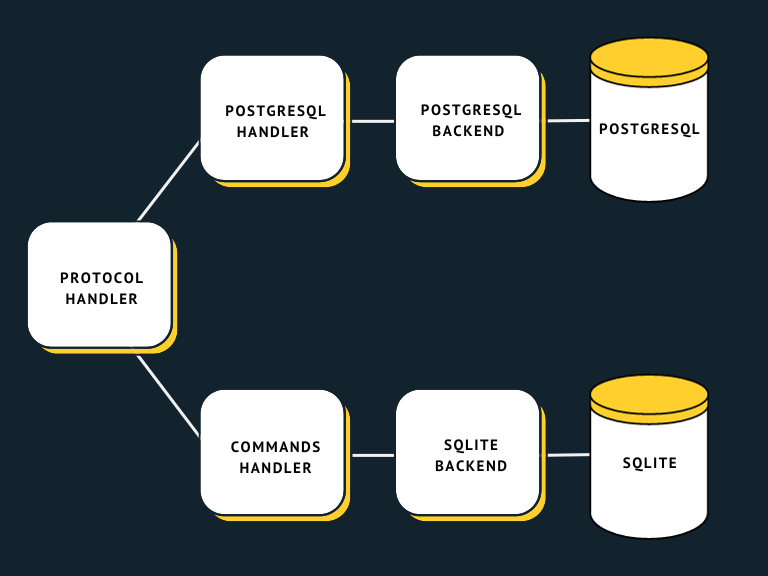
The common backend interface is relatively small and makes it easy to add new backends. For example, there is a single method that backends should implement to insert given documents. The code for processing ordered and unordered insertions is written once in the command handler; there is no need to repeat that logic for every backend. Of course, if there is some storage that could perform this operation more efficiently, there could be a separate optional method that could be implemented. Then the command handler could check if that method is implemented by the current backend and use it.
That architecture also allows us to add optional functionality to all backends at once.
For example, there is already a very early prototype of the "OpLog" functionality.
It works by wrapping insert, update, and delete methods of any backend and inserting documents
into operation log collection when wrapped methods succeed.
The more advanced backend-specific methods of implementing that functionality could be implemented if needed.
For example, PostgreSQL could use triggers for achieving better performance.
That leads us to the discussion of the FerretDB future.
The future
With the new backend architecture, it is now easier to contribute to FerretDB, and features can be added faster. This means that moving forward, it will be possible to make FerretDB compatible with MongoDB workloads much easier than before. And the resulting code will be easier to maintain as well.
In the coming weeks, we will be migrating our PostgreSQL backend onto the new architecture and releasing it without breaking changes. Our aim is to deliver all of these improvements without needing to migrate your data.
Additionally, adding support for MySQL has been one of the most popular feature requests to date. While our focus will remain on SQLite and PostgreSQL for now, with the new architecture in place, we are counting on the open-source community to help us create support for MySQL and other backends.
You can always see what else we have planned in our public roadmap. And if you want to contribute – you are more than welcome!