A Guide to Disaster Recovery for FerretDB with Elotl Nova on Kubernetes


Running a database without a disaster recovery process can result in loss of business continuity, resulting in revenue loss and reputation loss for a modern business.
Cloud environments provide a vast set of choices in storage, networking, compute, load-balancing and other resources to build out DR solutions for your applications. However, these building blocks need to be architected and orchestrated to build a resilient end-to-end solution. Ensuring continuous operation of the databases backing your production apps is critical to avoid losing your customers' trust.
Successful disaster recovery requires:
- Reliable components to automate backup and recovery
- A watertight way to identify problems
- A list of steps to revive the database
- Regular testing of the recovery process
This blog post shows how to automate these four aspects of disaster recovery using FerretDB, Percona PostgreSQL and Nova. Nova automates parts of the recovery process, reducing mistakes and getting your data back online faster.
Components overview
FerretDB is an open-source proxy that translates MongoDB wire protocol queries to SQL, with PostgreSQL or SQLite as the database engine.
Percona for PostgreSQL is a tool set to manage your PostgreSQL database system: it installs PostgreSQL and adds a selection of extensions that help manage the database.
Nova is a multi-cloud, multi-cluster control plane that orchestrates workloads across multiple Kubernetes clusters via user-defined policies.
Defining a Disaster Recovery setup for FerretDB + Percona Postgres
FerretDB operates as a stateless application, therefore during recovery Nova only needs to make sure it is connected to a primary PostgreSQL database.
To implement PostgreSQL's Disaster Recovery (DR), a primary cluster, standby cluster, and object storage, such as an S3 bucket, are required. The storage will be used for storing periodic backups performed on the primary cluster. The standby cluster will be configured as the backup location, so it is kept in-sync with the primary. When disaster strikes, the standby is set as a new primary to keep the database running (more details can be found here: Percona Blog).
For the entry point for our database, a proxy in front of the database directs communication to the appropriate instance.
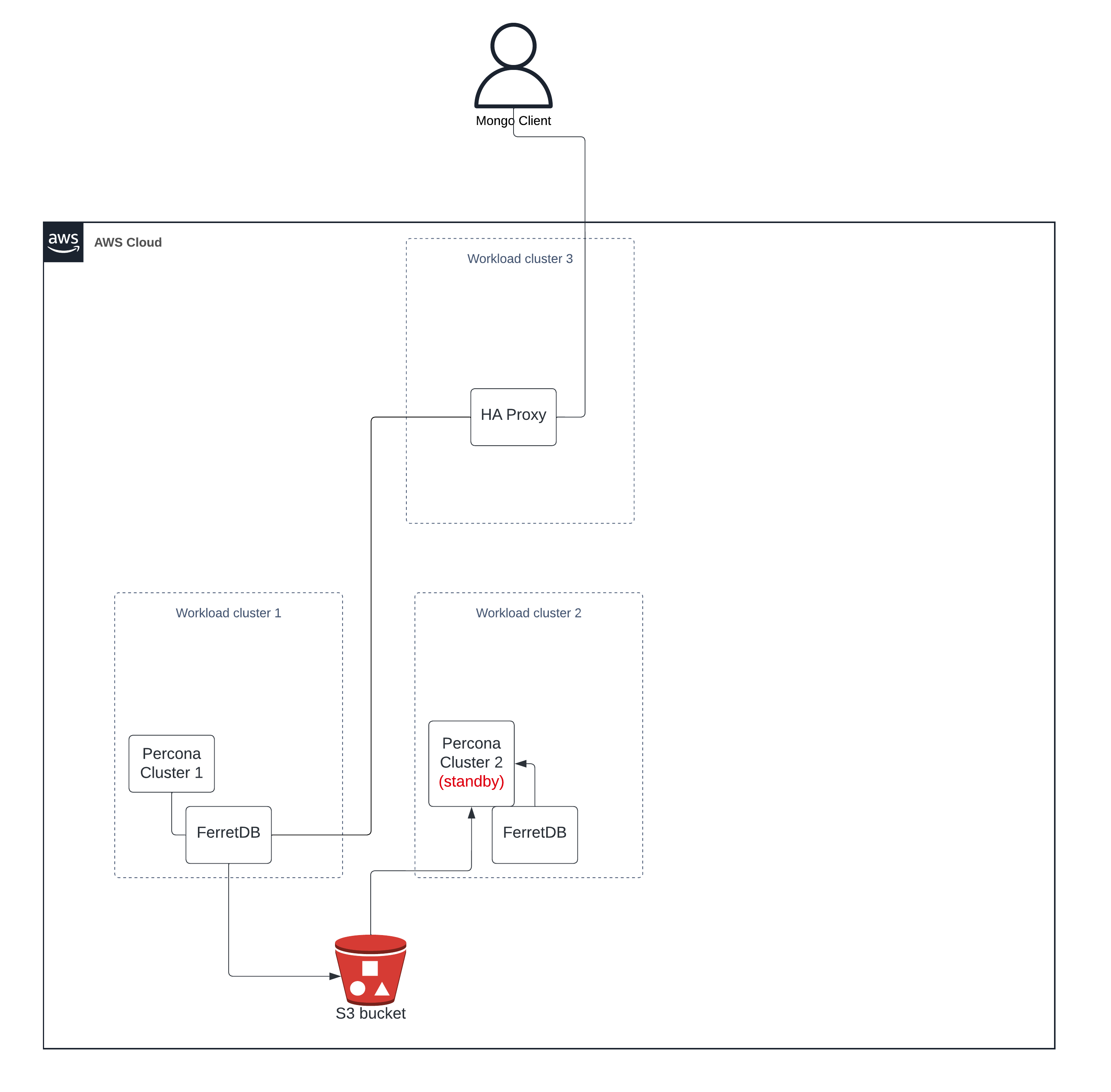
Basic setup
Setup involves three clusters:
- Workload Cluster 1 contains:
- Percona Operator
- PostgreSQL primary cluster
- FerretDB
- Workload Cluster 2 contains:
- Percona Operator
- PostgreSQL standby cluster
- FerretDB
- Workload Cluster 3 contains:
- HAProxy, the single entry point to FerretDB.
- HAProxy connected to FerretDB in cluster 1 (linked to the primary PostgreSQL).
- After recovery, HAProxy will be connected to FerretDB in cluster 2 (linked to the new primary PostgreSQL).
The proxy is a single point of failure, it is intentionally set up this way to simplify the demonstration of database recovery.
With the described setup in place, Nova can execute the following recovery steps if Cluster 1 fails:
- Set Percona cluster 2 as primary
- Set Percona cluster 1 as standby (You cannot have two primary clusters simultaneously in one setup as it would disrupt the backup process. If Cluster 1 is initially marked as failed due to network issues and Cluster 2 takes over, Nova must ensure that, if Cluster 1 becomes available again, it does not reconnect as the primary.)
- Connect HAProxy to FerretDB in cluster 2
Automating the setup and recovery execution
To simplify deployment across multiple servers, use Nova to deploy FerretDB, Percona Operator, and configure PostgreSQL and HAProxy. By setting up policies, Nova will direct workloads, along with their configurations, to the appropriate cluster. Detailed information about configuring policies in Nova are described in the Nova Documentation.
Enhanced setup
An additional Kubernetes cluster is required to host the Nova control plane, and Nova agents are incorporated into the existing Kubernetes clusters. This setup enables exclusive communication with the Nova control plane during the deployment and configuration of all components.
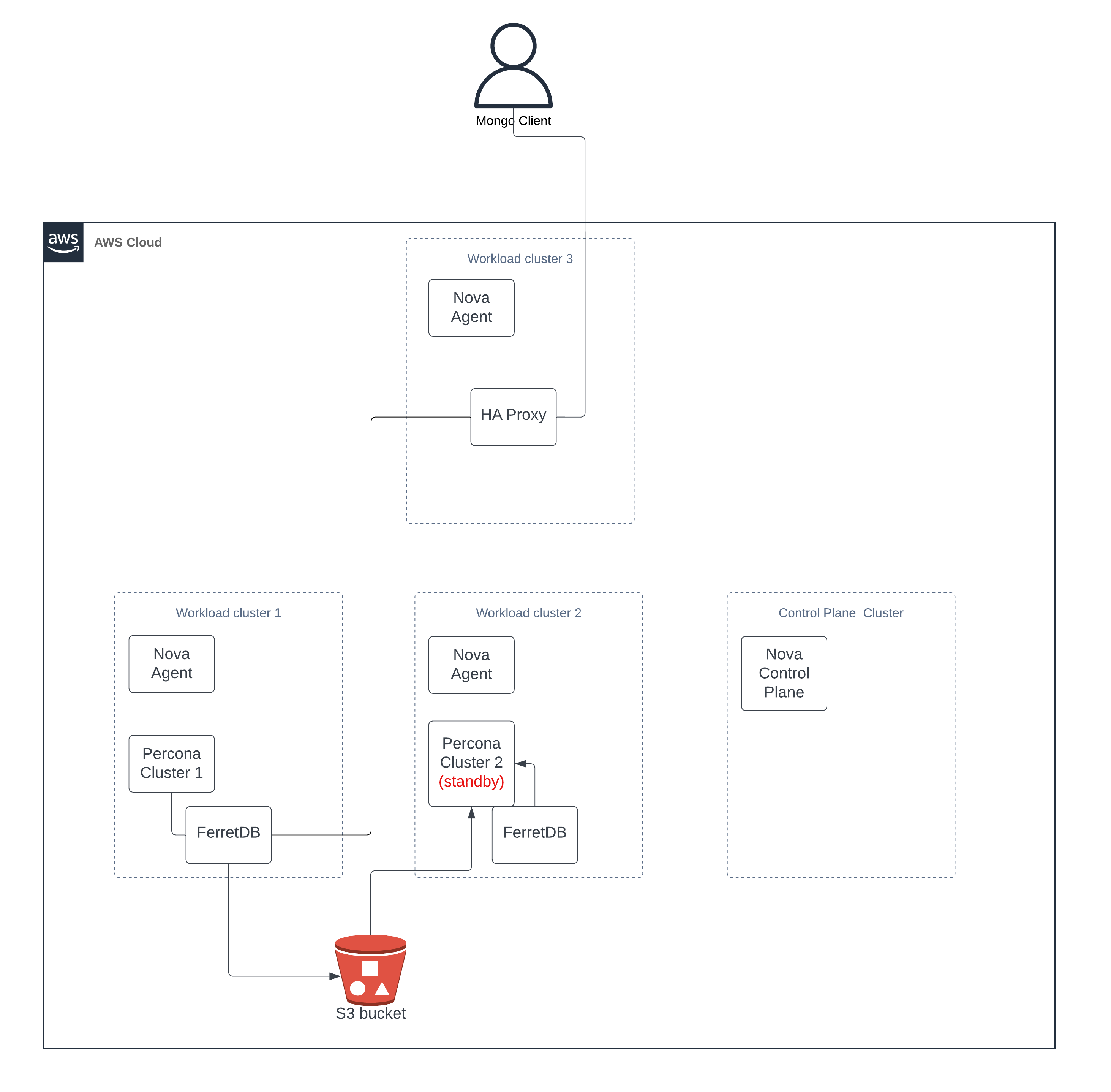
Nova Schedule Policy for FerretDB
With Nova scheduling policies, you can deploy all workloads and Nova will distribute them among clusters as needed. For example, the policy below spreads FerretDB deployment to two clusters with a different service name for each PostgresDB.
apiVersion: policy.elotl.co/v1alpha1
kind: SchedulePolicy
metadata:
name: spread-ferretdb
spec:
namespaceSelector:
matchExpressions:
- key: kubernetes.io/metadata.name
operator: Exists
resourceSelectors:
labelSelectors:
- matchLabels:
app: ferretdb
groupBy:
labelKey: app
clusterSelector:
matchExpressions:
- key: kubernetes.io/metadata.name
operator: In
values:
- cluster-1
- cluster-2
spreadConstraints:
spreadMode: Duplicate
topologyKey: kubernetes.io/metadata.name
overrides:
- topologyValue: cluster-1
resources:
- kind: Deployment
apiVersion: apps/v1
name: ferretdb
namespace: default
override:
- fieldPath: spec.template.spec.containers[0].env[0].value
value:
staticValue: postgres://cluster1-ha.psql-operator.svc:5432/zoo
- topologyValue: cluster-2
resources:
- kind: Deployment
apiVersion: apps/v1
name: ferretdb
namespace: default
override:
- fieldPath: spec.template.spec.containers[0].env[0].value
value:
staticValue: postgres://cluster2-ha.psql-operator.svc:5432/zoo
---
apiVersion: policy.elotl.co/v1alpha1
kind: SchedulePolicy
metadata:
name: psql-cluster-1-ferretdb
spec:
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: default
clusterSelector:
matchLabels:
kubernetes.io/metadata.name: cluster-1
resourceSelectors:
labelSelectors:
- matchLabels:
psql-cluster: cluster-1
---
apiVersion: policy.elotl.co/v1alpha1
kind: SchedulePolicy
metadata:
name: psql-cluster-2-ferretdb
spec:
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: default
clusterSelector:
matchLabels:
kubernetes.io/metadata.name: cluster-2
resourceSelectors:
labelSelectors:
- matchLabels:
psql-cluster: cluster-2
Recovery Plan
Now that the FerretDB is up and running, Nova will be configured to execute a recovery plan when something goes wrong. You just need to convert the recovery steps we outlined above into Nova's recovery plan. The Recovery Plan is a Kubernetes Custom Resource and looks as follows:
apiVersion: recovery.elotl.co/v1alpha1
kind: RecoveryPlan
metadata:
name: psql-primary-failover-plan
spec:
alertLabels:
app: example-app
steps:
- type: patch # set perconapgclusters 1 to standby
patch:
apiVersion: "pg.percona.com/v2beta1"
resource: "perconapgclusters"
namespace: "psql-operator"
name: "cluster1"
override:
fieldPath: "spec.standby.enabled"
value:
raw: true
patchType: "application/merge-patch+json"
- type: patch # set perconapgclusters 2 to primary
patch:
apiVersion: "pg.percona.com/v2beta1"
resource: "perconapgclusters"
namespace: "psql-operator"
name: "cluster2"
override:
fieldPath: "spec.standby.enabled"
value:
raw: false
patchType: "application/merge-patch+json"
- type: readField # read ferretdb service hostname in cluster 2
readField:
apiVersion: "v1"
resource: "services"
namespace: "default"
name: "ferretdb-service-2"
fieldPath: "status.loadBalancer.ingress[0].hostname" outputKey: "Cluster2IP"
- type: patch # update HAProxy to point to ferretdb service in cluster 2
patch:
apiVersion: "v1"
resource: "configmaps"
namespace: "psql-operator"
name: "haproxy-config"
override:
fieldPath: "data"
value:
raw: {"haproxy.cfg": "defaults\n mode tcp\n timeout connect 5000ms\n timeout client 50000ms\n timeout server 50000ms\n\nfrontend fe_main\n bind *:5432\n default_backend be_db_2\n\nbackend be_db_2\n server db2 {{.Values.Cluster2IP}}:27017 check"}
patchType: "application/merge-patch+json"
Triggering the recovery plan execution
Nova exposes a webhook endpoint that matches recovery plans with the alert's label. You can send an alert manually using a tool like curl. Alternatively, you can use an alert system, like AlertManager + Prometheus, which will automatically notify Nova when a certain metric goes beyond a set limit.
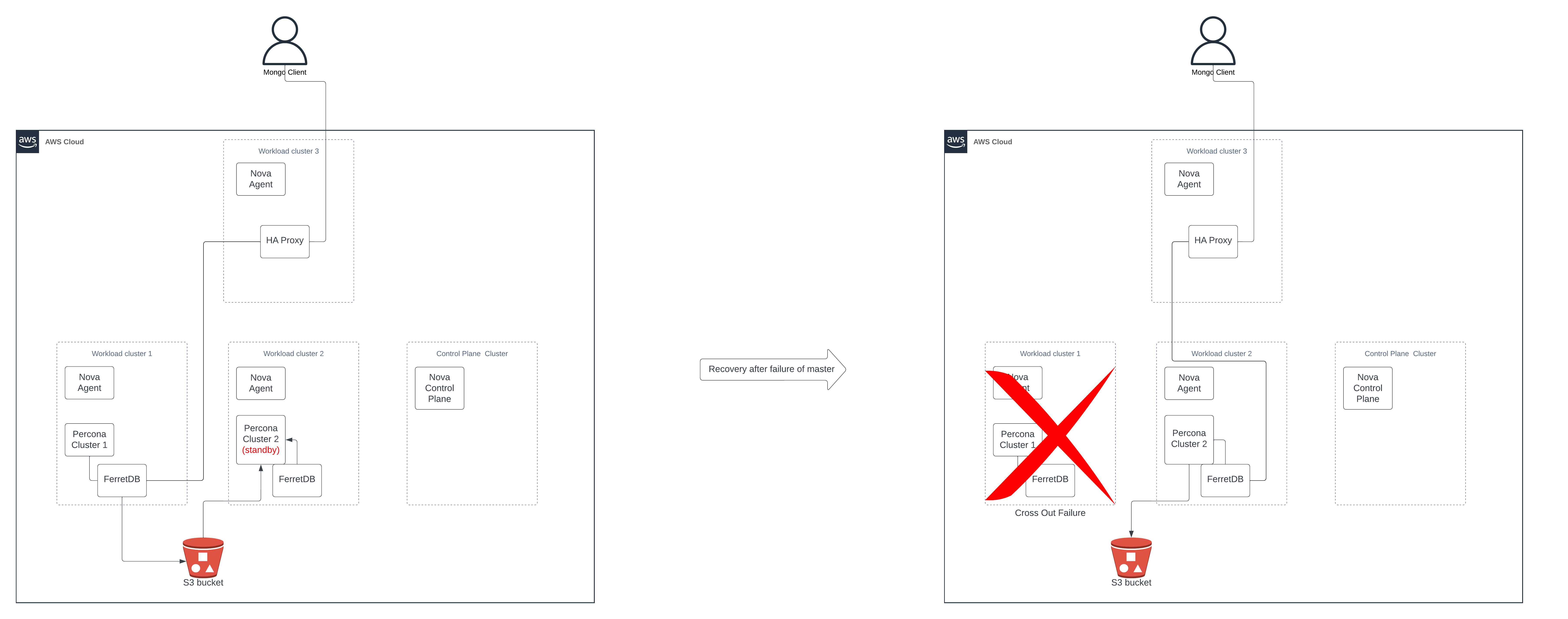
Summary
The above steps, process, and execution has resulted in a successful setup of FerretDB to autonomously recover from disasters, such as region-wide failures. This configuration ensures seamless healing in case of unexpected events, greatly improving the resilience of the FerretDB deployment.
To learn more about FerretDB, see the documentation.
To learn more about Nova, see Nova Documentation and try it for free.
Thanks to Selvi Kadirvel, Henry Precheur, Janek Baranowski , Pawel Bojanowski, Justin Willoughby, Madhuri Yechuri from Elotl team for reviewing this blog post.